pprof Options: -u, --url= Base URL of your Go program (default: http://localhost:8080) --suffix= URL path of pprof profile (default: /debug/pprof/profile) -b, --binaryinput= File path of previously saved binary profile. (binary profile is anything accepted by https://golang.org/cmd/pprof) --binaryname= File path of the binary that the binaryinput is for, used for pprof inputs -t, --seconds= Number of seconds to profile for (default: 30) --pprofArgs= Extra arguments for pprof
Output Options: -f, --file= Output file name (must be .svg) (default: torch.svg) -p, --print Print the generated svg to stdout instead of writing to file -r, --raw Print the raw call graph output to stdout instead of creating a flame graph; use with Brendan Gregg's flame graph perl script (see https://github.com/brendangregg/FlameGraph) --title= Graph title to display in the output file (default: Flame Graph) --width= Generated graph width (default: 1200) --hash Colors are keyed by function name hash --colors= set color palette. choices are: hot (default), mem, io, wakeup, chain, java, js, perl, red, green, blue, aqua, yellow, purple, orange --cp Use consistent palette (palette.map) --reverse Generate stack-reversed flame graph --inverted icicle graph Help Options: -h, --help Show this help message
# signal.set_wakeup_fd closes a race condition in event loops: # a signal may arrive at the beginning of select/poll/etc # before it goes into its interruptible sleep, so the signal # will be consumed without waking the select. The solution is # for the (C, synchronous) signal handler to write to a pipe, # which will then be seen by select. # # In python's signal handling semantics, this only matters on the # main thread (fortunately, set_wakeup_fd only works on the main # thread and will raise a ValueError otherwise). # # If someone has already set a wakeup fd, we don't want to # disturb it. This is an issue for twisted, which does its # SIGCHLD processing in response to its own wakeup fd being # written to. As long as the wakeup fd is registered on the IOLoop, # the loop will still wake up and everything should work.
# wakeup_fd是用来唤醒主事件循环(信号唤醒,或者从别的线程唤醒主线程)。 old_wakeup_fd = None if hasattr(signal, 'set_wakeup_fd') and os.name == 'posix': # requires python 2.6+, unix. set_wakeup_fd exists but crashes # the python process on windows.
# Python2.6版本以上,Unix-like系统中,signal模块支持set_wakeup_fd方法。 # Windows上siganl存在该方法,但是会crash。 try: old_wakeup_fd = signal.set_wakeup_fd(self._waker.write_fileno()) if old_wakeup_fd != -1: # Already set, restore previous value. This is a little racy, # but there's no clean get_wakeup_fd and in real use the # IOLoop is just started once at the beginning. signal.set_wakeup_fd(old_wakeup_fd) old_wakeup_fd = None except ValueError: # Non-main thread, or the previous value of wakeup_fd # is no longer valid. # 参考signal的官方手册,set_wakeup_fd仅可在主线程中调用。 old_wakeup_fd = None
try: whileTrue: # Prevent IO event starvation by delaying new callbacks # to the next iteration of the event loop. # ncallbacks记录了此次循环的回调函数个数,新增加的回调函数将要在下次循环被调用。 ncallbacks = len(self._callbacks)
# Add any timeouts that have come due to the callback list. # Do not run anything until we have determined which ones # are ready, so timeouts that call add_timeout cannot # schedule anything in this iteration. due_timeouts = [] # 即将超时的任务。 if self._timeouts: now = self.time() while self._timeouts: if self._timeouts[0].callback isNone: # The timeout was cancelled. Note that the # cancellation check is repeated below for timeouts # that are cancelled by another timeout or callback. heapq.heappop(self._timeouts) self._cancellations -= 1 elif self._timeouts[0].deadline <= now: due_timeouts.append(heapq.heappop(self._timeouts)) else: break if (self._cancellations > 512and self._cancellations > (len(self._timeouts) >> 1)): # Clean up the timeout queue when it gets large and it's # more than half cancellations. # 如果定时任务取消数量大于512,并且超过总定时任务的半数,则清理self._timeouts,并重新平衡堆。 self._cancellations = 0 self._timeouts = [x for x in self._timeouts if x.callback isnotNone] heapq.heapify(self._timeouts)
for i in range(ncallbacks): # 执行回调函数。 self._run_callback(self._callbacks.popleft()) for timeout in due_timeouts: # 执行定时任务。 if timeout.callback isnotNone: self._run_callback(timeout.callback) # Closures may be holding on to a lot of memory, so allow # them to be freed before we go into our poll wait. due_timeouts = timeout = None# 防止内存泄漏
if self._callbacks: # If any callbacks or timeouts called add_callback, # we don't want to wait in poll() before we run them. # 如果发现新增的_callbacks,(回调函数执行时加入了新的回调函数)。 poll_timeout = 0.0 elif self._timeouts: # If there are any timeouts, schedule the first one. # Use self.time() instead of 'now' to account for time # spent running callbacks. poll_timeout = self._timeouts[0].deadline - self.time() # 距离将来最近一次定时任务的时间,wait该时间。 poll_timeout = max(0, min(poll_timeout, _POLL_TIMEOUT)) else: # No timeouts and no callbacks, so use the default. # 未发现新的回调函数与定时任务,则调用poll,等待IO事件,超时事件为3600秒。 poll_timeout = _POLL_TIMEOUT
if self._blocking_signal_threshold isnotNone: # clear alarm so it doesn't fire while poll is waiting for # events. signal.setitimer(signal.ITIMER_REAL, 0, 0)
try: # 等待IO事件,events_pairs内容为:[(fd, events), (fd, events), ] event_pairs = self._impl.poll(poll_timeout) except Exception as e: # Depending on python version and IOLoop implementation, # different exception types may be thrown and there are # two ways EINTR might be signaled: # * e.errno == errno.EINTR # * e.args is like (errno.EINTR, 'Interrupted system call')
# poll陷入内核态以后,进程捕获到的信号会导致poll wait结束,并且错误码为EINTR。 if errno_from_exception(e) == errno.EINTR: continue else: raise
if self._blocking_signal_threshold isnotNone: signal.setitimer(signal.ITIMER_REAL, self._blocking_signal_threshold, 0)
# Pop one fd at a time from the set of pending fds and run # its handler. Since that handler may perform actions on # other file descriptors, there may be reentrant calls to # this IOLoop that modify self._events self._events.update(event_pairs) while self._events: fd, events = self._events.popitem() try: # 获取file-like object,与IO事件的处理函数handler。 fd_obj, handler_func = self._handlers[fd] # 调用handler,处理fd_obj上发生的events事件, # handler_func在add_handler时候,加入了对事件处理的wraps。 handler_func(fd_obj, events) except (OSError, IOError) as e: if errno_from_exception(e) == errno.EPIPE: # Happens when the client closes the connection # 客户端关闭了同服务器的连接。 pass else: # 处理异常。 self.handle_callback_exception(self._handlers.get(fd)) except Exception: self.handle_callback_exception(self._handlers.get(fd)) fd_obj = handler_func = None
finally: # reset the stopped flag so another start/stop pair can be issued self._stopped = False if self._blocking_signal_threshold isnotNone: signal.setitimer(signal.ITIMER_REAL, 0, 0) # 还原前一个IOLoop实例(作者也说了这种情况基本没有...) IOLoop._current.instance = old_current if old_wakeup_fd isnotNone: signal.set_wakeup_fd(old_wakeup_fd)
All Python objects ultimately share a small number of fields at the beginning of the object’s representation in memory. These are represented by thePyObject and PyVarObject types, which are defined, in turn, by the expansions of some macros also used, whether directly or indirectly, in the definition of all other Python objects.
示例运行结果为4,比实际引用数量(a, b, c)多1,那么为什么会这样呢,`sys.getrefcount`的文档作出了说明:
>Return the reference count of the *object*. The count returned is generally one higher than you might expect, because it includes the (temporary) reference as an argument to [`getrefcount()`](https://docs.python.org/2.7/library/sys.html#sys.getrefcount).
把对象当做参数调用`sys.getrefcount`方法会增加对象的一个临时引用计数。
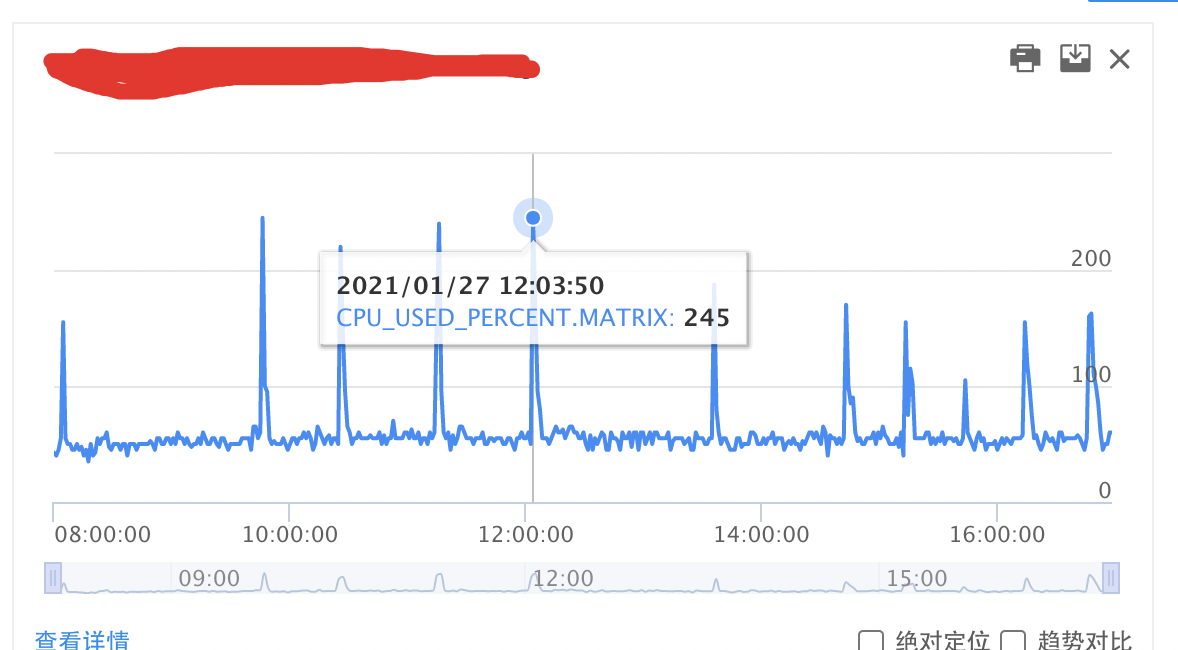
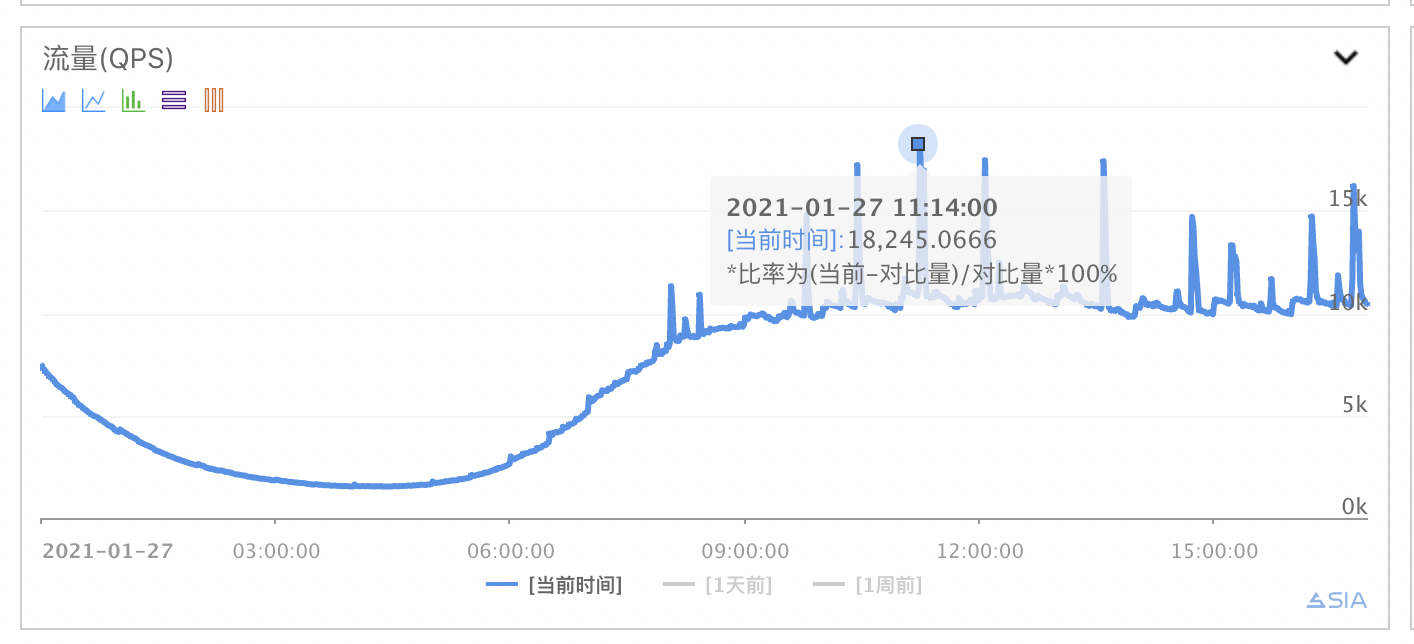
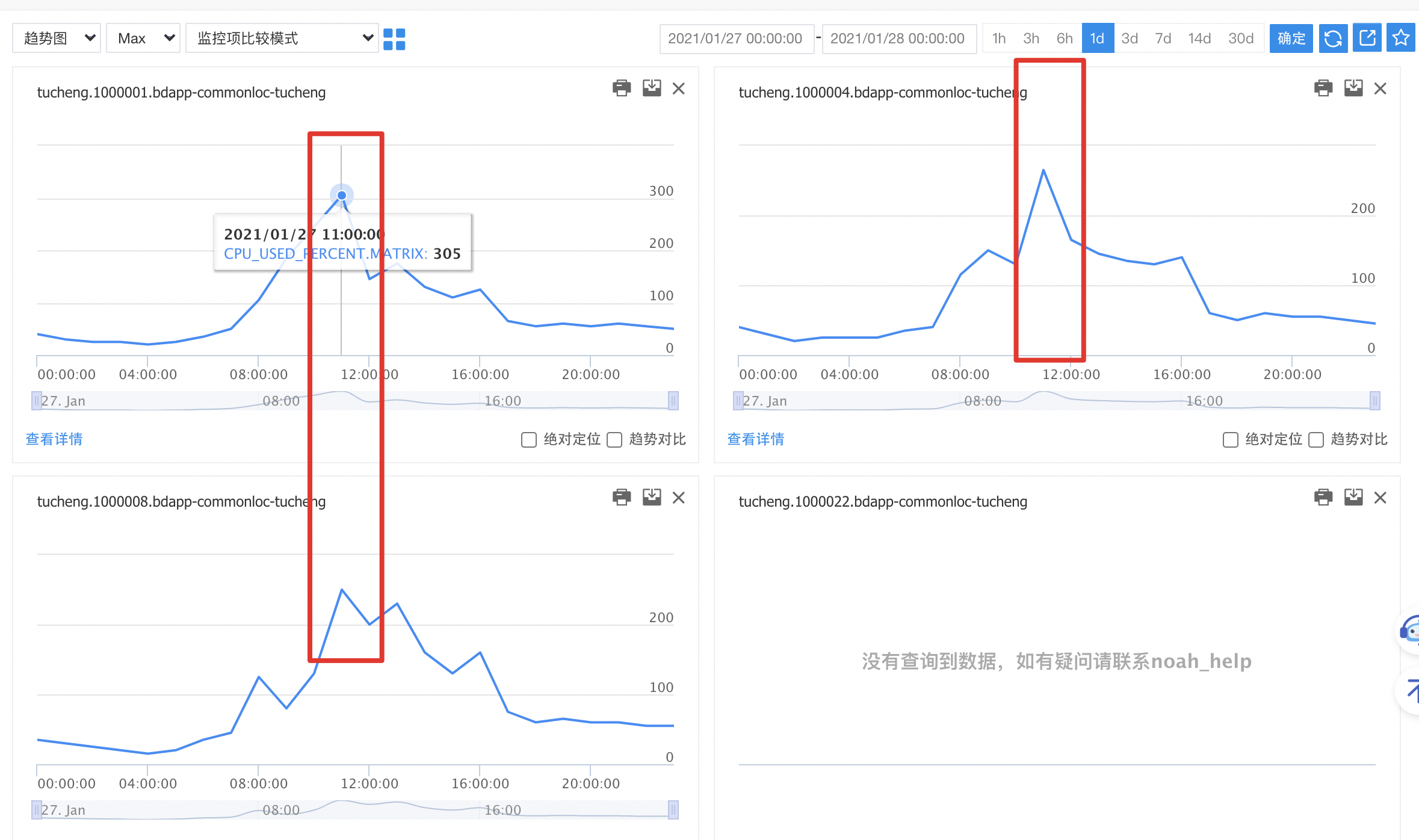
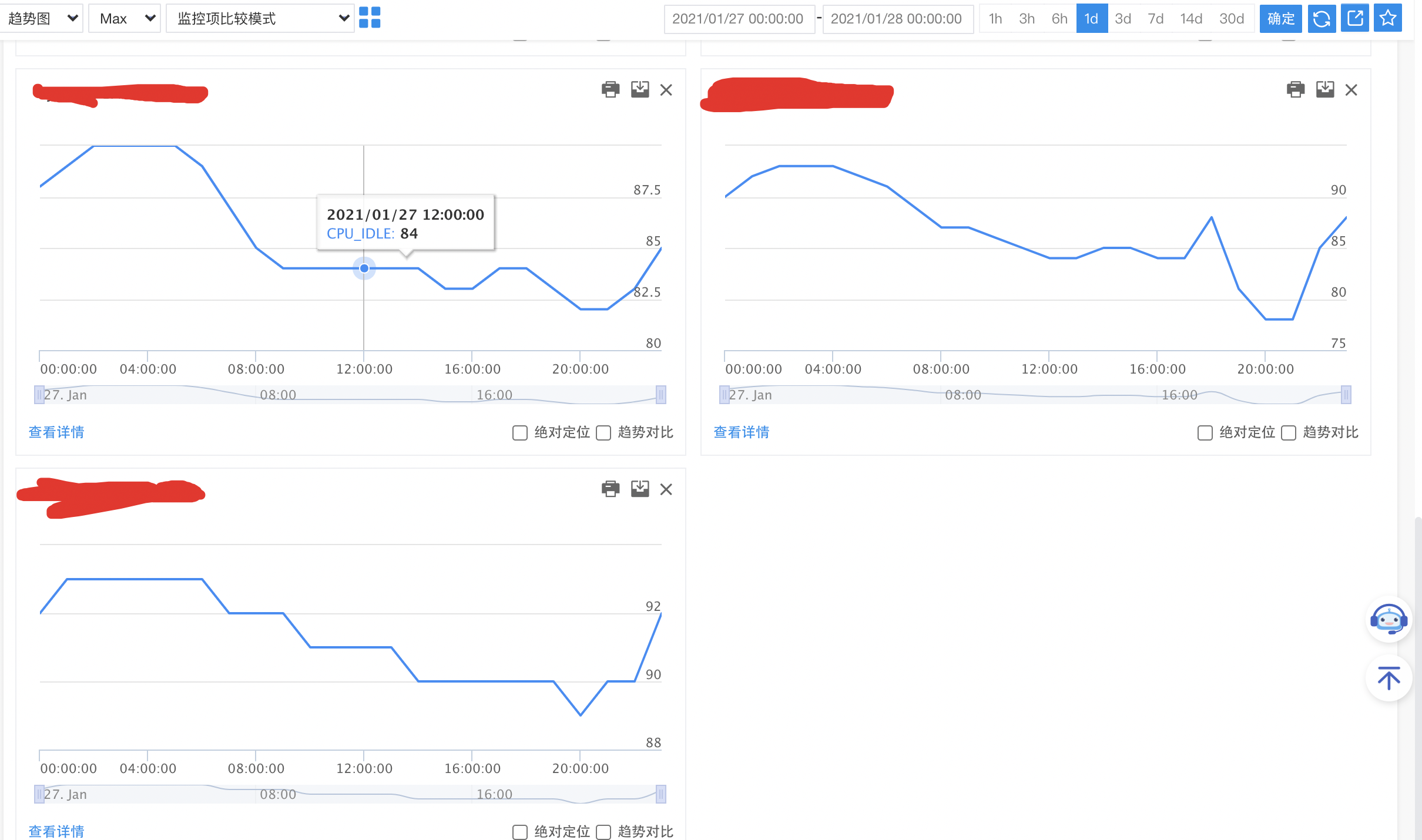


{kind=link}