服务雪崩历险记(上)
服务雪崩——作为微服务架构中的经典问题,之前只是在技术博客中看到过,没想到自己有一天也遇到了,由于首次处理此类问题,经验较为欠缺,走了一些弯路,在此记录排查思路与解决方案,服务雪崩的概念可以参考网上技术文章,在此不做过多赘述。
线上现象
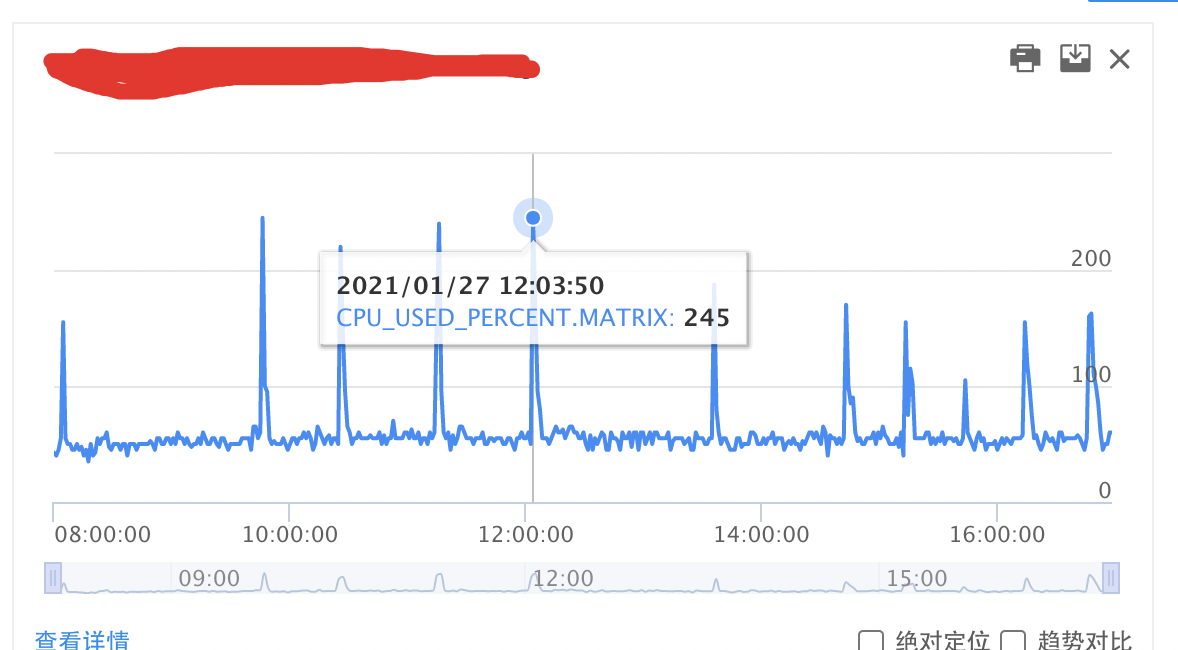
今天上午刚刚到公司,便收到【天气服务】CPU使用率超限报警,上午一般是百度APP流量低峰期,因此笔者感觉比较奇怪,于是便打开报警链接,发现北京机房实例CPU使用率达到了惊人的245%**,远远超过了70%**的阈值(事后非常庆幸,笔者撰文时所有容器已开启资源硬限,雪崩发生时尚未开启CPU资源硬限,否则服务可用性可能会跌到个位数=_=),如图所示:
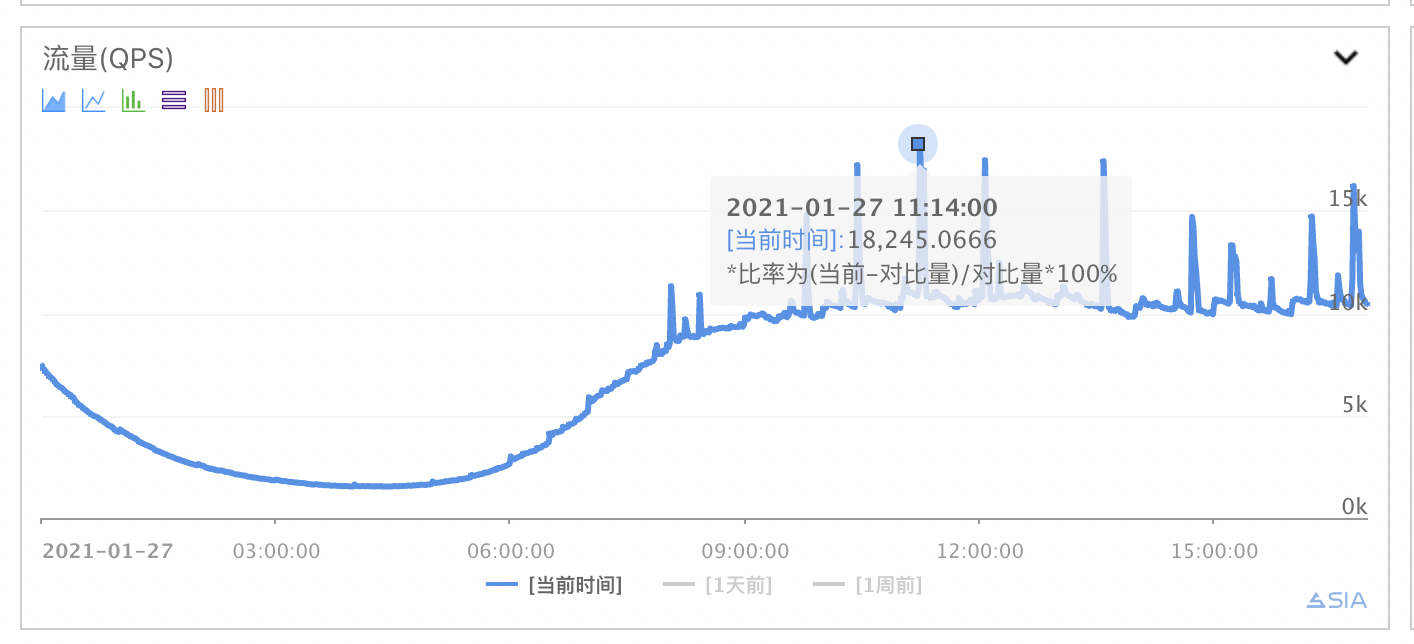
笔者第一时间打开业务监控,查看接口监控指标。如下图,可以明显看到接口流量有若干个波峰,最高的波峰上涨了约80%(8000Q左右)。情理之中,意料之外的是——接口可用性、接口平响同样出现若干个波峰,依赖的所有下游服务可用性均下跌严重。很明显【天气服务】出现了雪崩的迹象,但全线上涨的监控指标,掩盖了问题发生的根源,无从下手定位问题原因。雪崩的时候没有一片雪花是无辜的。
问题定位
初步排查
因为无【服务雪崩】相关排查与处理经验,未能直击要害点。根据【止损优先】的原则,笔者凭直觉(经验),先列出可能的原因,尝试止损:
- Go模块未知Bug被触发(例如:Goroutine泄露、full GC),导致CPU使用率急剧飙升,流量急剧升高,下游服务可用性急剧变差;
- 端发生大规模崩溃,频繁重启,流量上涨,导致CPU过载;
- 下游服务不稳定,导致【天气接口】大量超时,触发上游服务重试,导致CPU使用率飙升;
首先,选择三台问题实例(容器),查看实例CPU使用率监控指标,三台实例CPU使用率波峰出现时间点完全一致,且且内存使用率、已打开文件描述符等等监控均未见异常,基本排除实例内Go模块未知Bug引起CPU使用率飙升,进而引起连锁反应可能性。深入跟踪,查看三台实例所在物理机的CPU使用率(未开启资源硬限,混布服务存在资源侵占的可能性),CPU IDLE指标较高,计算资源充裕,排除服务混布,其它服务实例资源占用的可能性(**注:CPU使用率升高与流量升高,是个鸡生蛋蛋生鸡的问题,CPU使用率升高,会导致部分请求处理不及时,引发上游服务重试,导致流量上涨、可用性下跌等等,所以不能武断**)。综合实例CPU使用率与物理机CPU使用率,基本排除CPU性能瓶颈(延伸问题:若容器开启硬限制,如何排除)。
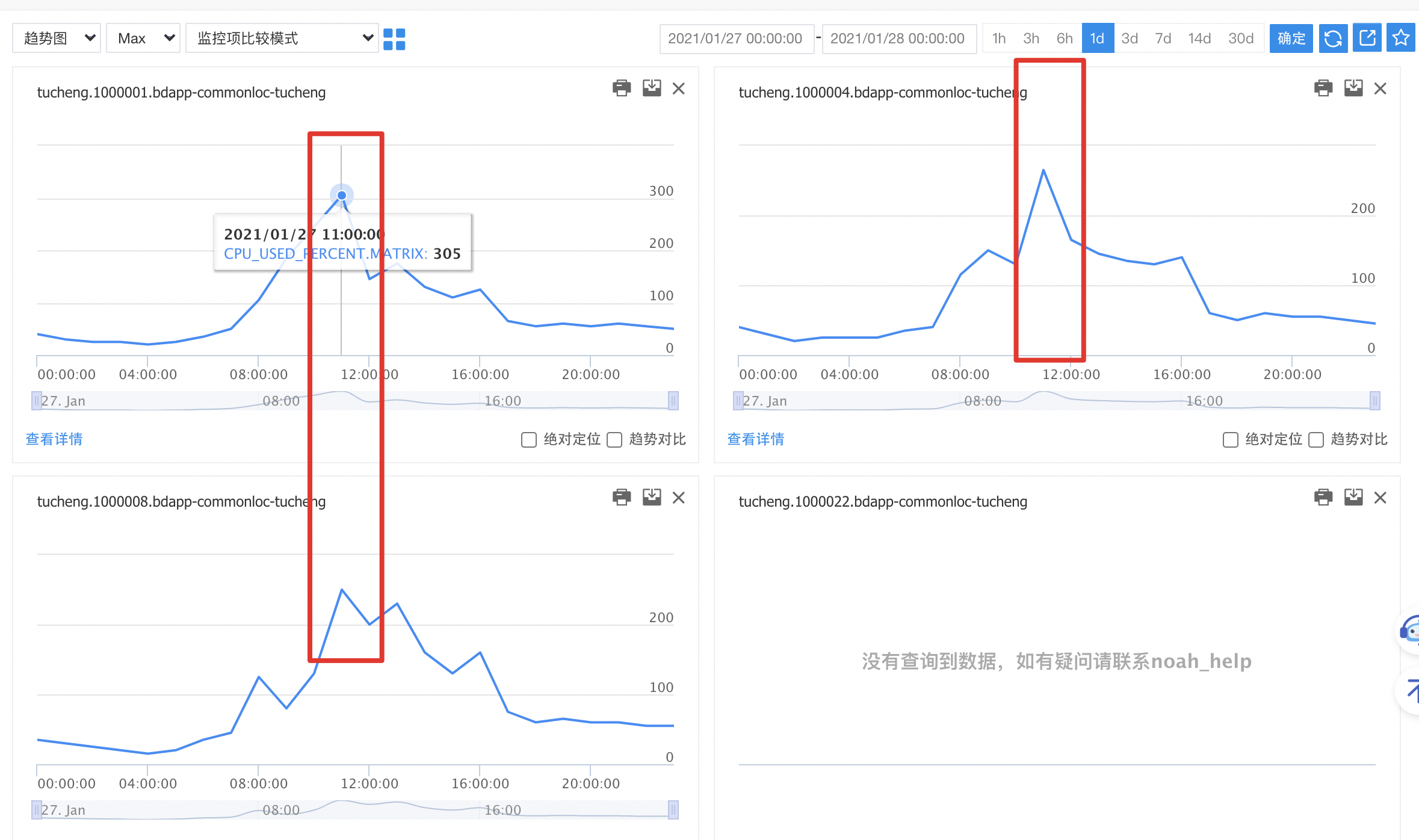
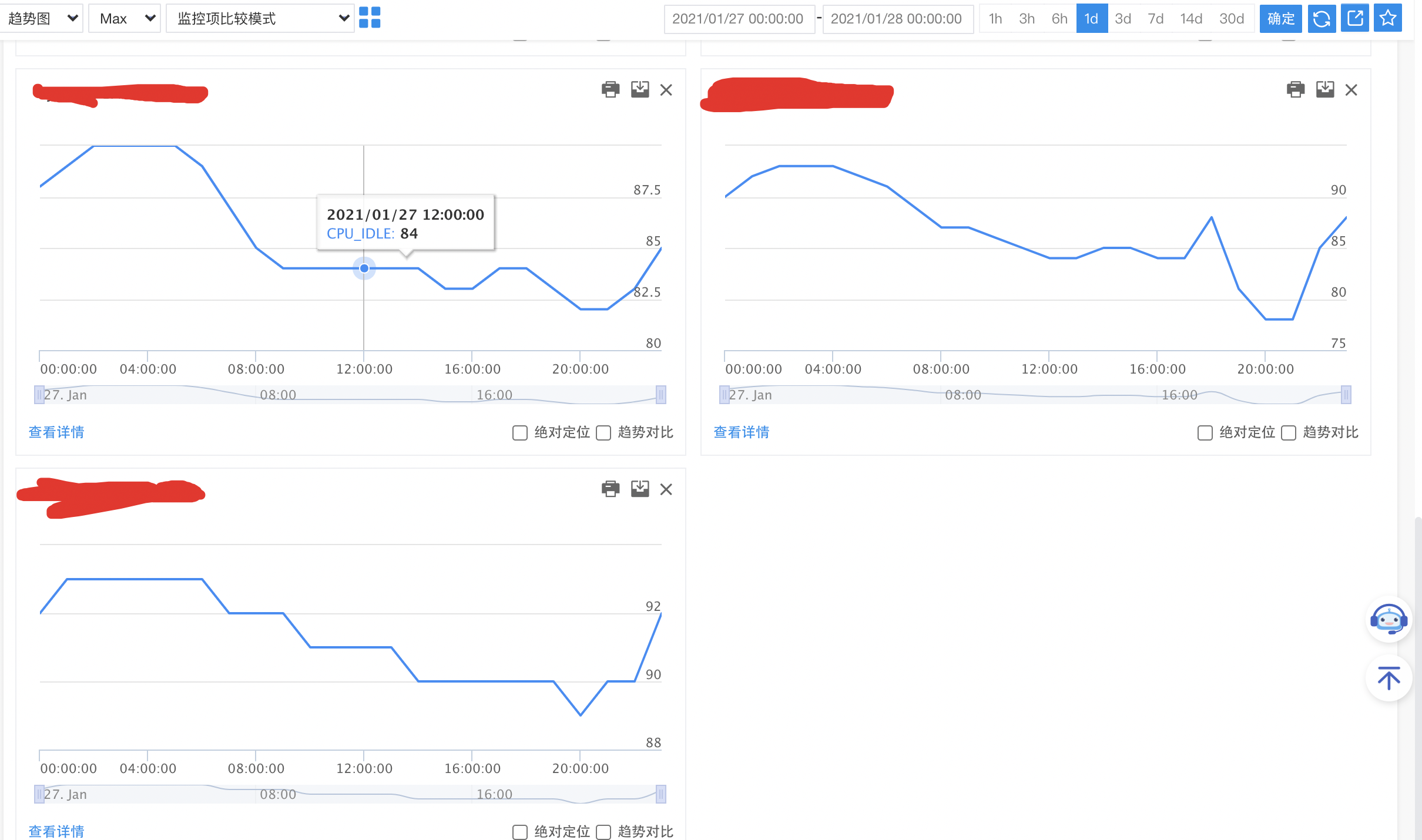
端发生大规模崩溃,【天气服务】接口流量会上涨,调用的其它接口都会比较明显的上涨。但观察其它接口正常,端崩溃率监控正常,可能性2排除。
在可能性1与可能性2基本排除后,**笔者几乎可以肯定是下游服务可用性出现波动,拖累天气服务超时,触发接入层重试**,但监控中所有下游服务可用性(上游服务调用下游成功率)均大幅度下跌,无参考价值。分析线上RPC请求日志,失败原因均为”request canceled (client.timeout exceeded while awaiting header”,即读超时。一般情况下,因CPU使用率升高导致请求下游服务失败,在建立连接阶段就失败了,此处发生的错误为读超时,更加坚定笔者的判断。看上去真凶呼之欲出了,诡异的打脸马上来了,询问了所有下游业务方,业务方均反馈服务流量有上涨,但服务可用性、平响、CPU使用率均正常。
尝试止损
虽然尚未完全定位原因,但基本可以确定流量上涨的原因为【天气服务】上游服务重试导致的,『请求重试』加重了系统的负载,移除上游服务的重试应当是有效的。【天气服务】架构图如下(基于安全考虑,已屏蔽细节,实际架构有出入,不影响理解):
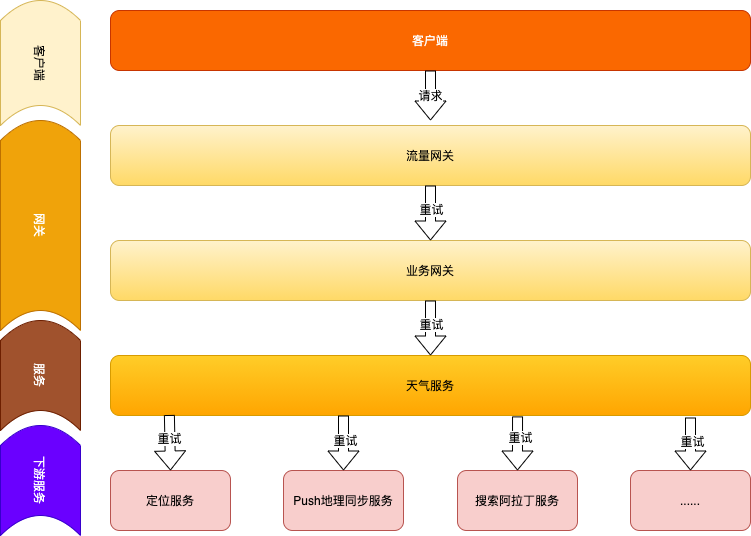
可以看到【流量网关】 => 【业务网关】=> 【天气服务】=> 【下游服务】存在3层重试,假如相邻的上下两层,请求超时,触发重试,到【下游服务】的流量最大会被放大至正常流量的8倍(2^3=8),很容易发生服务雪崩。流量网关,因接入了众多产品线,摘除『重试』风险较大,在【业务网关】与【天气服务】这两层,将『重试』逻辑移除。【天气服务】与【下游服务】流量逐渐下降,CPU使用率开始逐渐下降,止损操作已生效。
问题定位
摘除【业务网关】与【天气服务】的请求『重试』之后,【天气服务】流量趋于正常。因为【流量网关】『重试』尚未摘除,【天气服务】流量波峰与CPU波峰依然存在,参考价值依然不大。下游服务较为明显,陆续恢复正常,除了——Push地址位置同步服务。显然该服务是此次雪崩的真凶,那么为什么业务方观察的现业务可用性、平响、CPU使用率均正常,如此诡异呢。
长尾请求
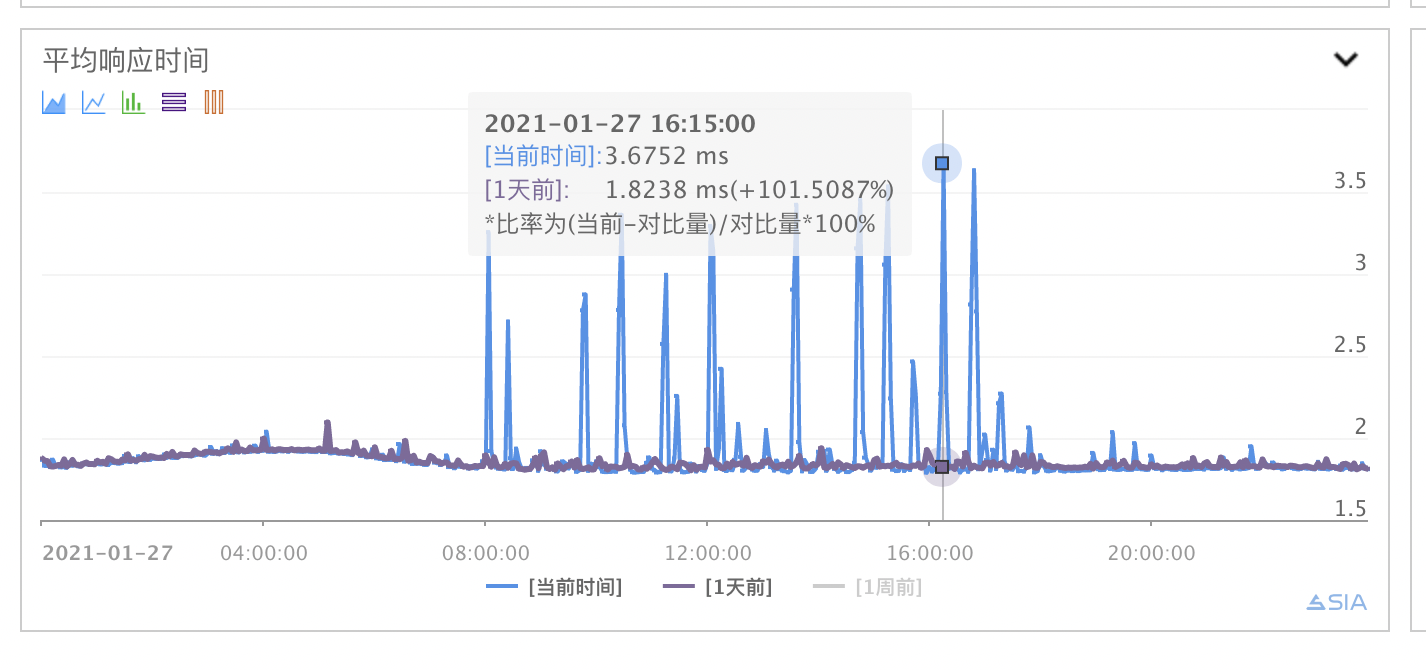
笔者在将【天气服务】请求Push地址位置同步服务Timeout时间调小进行止损的同时,开始分析原因,因为RPC报错日志大多数是读超时,首先想到的便是存在长尾请求(有关长尾请求与分位时参考笔者上一篇博文:https://keepalive555.github.io/2020/09/24/%E9%95%BF%E5%B0%BE%E8%AF%B7%E6%B1%82/),统计RPC日志85分位时如下(实际上请求该服务的RPC日志50分位时也将近400ms):

而业务方监控平响峰值在5ms以内(如图所示),即使RPC日志中前50%请求耗时为0ms,接口平响也有200ms,相差40倍。于是笔者与业务方RD开始梳理请求全链路,查找线索。
请求链路梳理
与业务方RD沟通后得知,下游业务采用『Nginx+PHP』的部署方式,每台实例前端均部署一台Nginx用作反向代理, 若干PHP进程(线程)处理请求。请求链路:【天气服务】=> 【实例Nginx】=>【业务方PHP进程】。业务方RD在Nginx日志中发现了大量HTTP 499错误码的请求,HTTP 499表示客户端因请求超时关闭请求,与【天气服务】RPC日志表现一致,耗时500ms,问题基本定位——**495ms的平响时间差是在【实例Nginx】转发至【业务方PHP进程】的过程中产生的**。
由于Nginx日志可供参考的信息有限,在OP同学的帮助下最终定位了原因——PHP的虚拟机Worker线程处理能力达到了上限,后续到达的请求排队等候处理,直至超时,**类似于限流算法中的漏桶算法**。这也是业务服务可用性、平响、CPU使用率均正常这种诡异现象的原因。
导火索
原因已定位,那导致请求堆积的罪魁祸首是什么呢——Push消息推送。年底运营活动较多,通过Push渠道进入百度APP的用户变多,下游业务吞吐量见顶。
事件复盘
“重试”属于控制论中的“正反馈”,会逐渐增强“”活动“——“雪崩”触发”重试”,“重试”强化“雪崩”程度,所以若发生“服务雪崩”可以且应当首先考虑调整“重试”策略。此次【服务雪崩】发生的逻辑链如下:
- 年底各业务方运营活动增多,Push推送频繁,“Push集群”流量逐渐上涨
- “Push集群”实例PHP虚拟机Worker线程全部被占用,并发处理能力达到上限
- “天气服务”请求“Push服务”,PHP虚拟机在处理其它请求,请求排队,读超时,此次请求失败
- “天气服务”请求”Push服务”超时,触发RPC请求重试,“天气服务”再次请求“Push服务”
- “天气请求”整体处理超时,触发“天气服务”上游“业务网关”重试策略,发起天气请求
- “天气服务”再次对所有“下游服务”发起请求,流量被放大到至4倍
- 因为下游所有服务负载加大,“业务网关”处理”天气请求”超时,触发“流量网关”请求重试
- “天气服务”再次对所有“下游服务”发起请求,流量被放大到至8倍
- “天气服务”所有下游服务流量上涨、可用性均下跌、平响升高
- “服务雪崩”ಥ_ಥ
服务雪崩解决方案
由于【天气服务】是由PHP模块迁移而来,尚未接入手百的Service Mesh,所以止损方案有限。服务雪崩是微服务架构中常见的问题,解决方案也比较成熟,笔者在下一篇博文中讲述,常见方案参考:
- 入口流量限流
- 访问下游服务增加断路器
- 异步请求弱依赖服务
- Locality-aware load balancing路由算法
- ……

